The Data Fabric Universe [Infographic]
March 11, 2019 | By: Kirk Newell
Companies today recognize that exploiting the full value of their enterprise data to enable expanded use of analytics is an essential competitive battleground of the future. Data assets from operational and BI systems, big data sources, and unstructured and the cloud offer a competitive edge for those companies who can become data and analytic experts today.
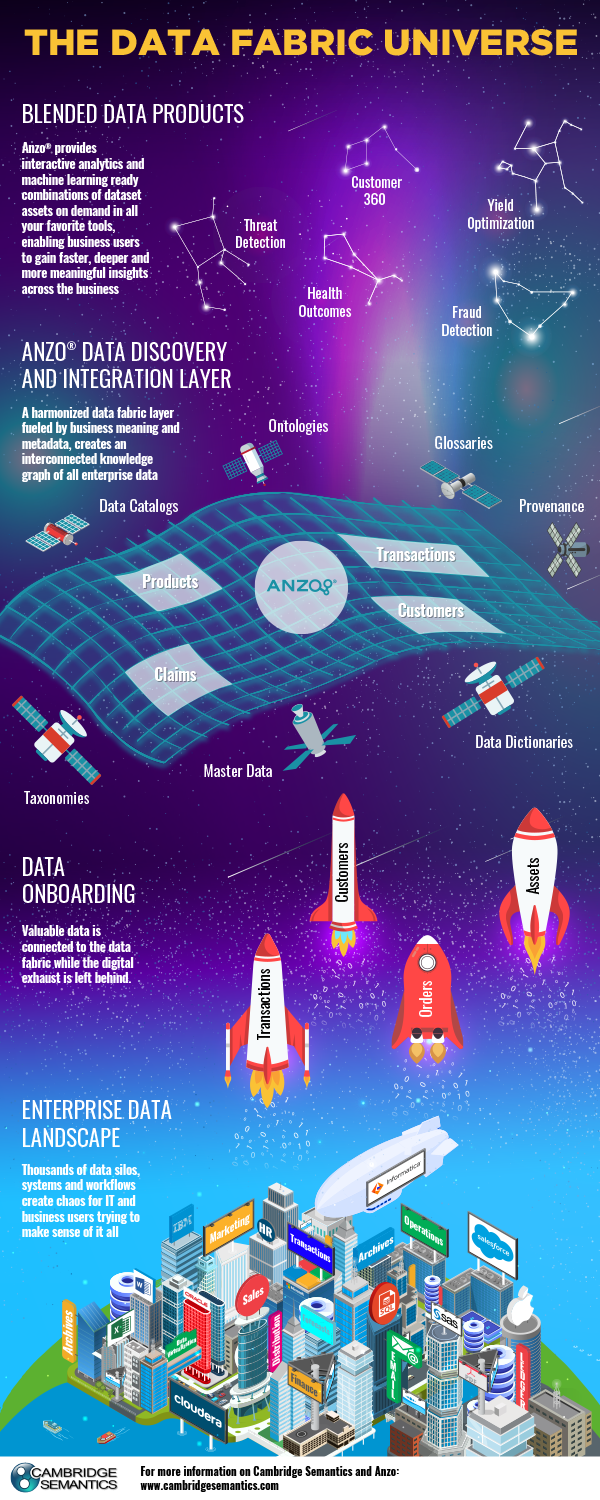
At Cambridge Semantics, we are focused on empowering companies to expand and accelerate the delivery of analytics-ready data to their business users by implementing a data discovery and integration layer as part of a modern data management architecture called the Enterprise Data Fabric. This discovery and integration layer sits above the company’s enterprise data assets and provides data consumers with a connected business-oriented map of enterprise data. People across the business with data or analytic needs use that map to explore, understand, connect and blend data in analytic-ready data sets that combine any data from any system across the enterprise.
Delivering this layer is our product, Anzo, a modern data discovery and integration platform that lets business users find, connect, and blend enterprise data into analytic-ready datasets. Anzo maps enterprise data to document its location, content, and contextual business meaning; exposes connections between datasets, and enables rapid visual data exploration and discovery. With Anzo data scientists and other data consumers in the business build blended analytic-ready data sets by iteratively cleansing, transforming, aligning and linking data from multiple previously disconnected enterprise data platforms. Anzo includes a robust set of enterprise-scale governance capabilities, making it easier and faster to ensure that all data is completely protected and secured from data ingestion through delivery.
It’s a lightweight overlay on your existing enterprise data management landscape. It’s installed in a couple of hours and can be up and running providing your business users with access to analytic-ready data within a couple of days. It works with all the data you have, including structured and unstructured data. Separate built-in data pipelines automate the process of on-boarding structured data like relational databases or flat files, and unstructured data like PDFs or documents. It works seamlessly alongside existing ETL or data replication tools, consuming data or metadata produced by those pipes, while also providing an alternate modern way for the organization to provide business users with analytic-ready data sets going forward.
This infographic helps visualize the architecture of the Enterprise Data Fabric. Interested in learning more about Data Fabric design? See the Gartner report.
You can click on the image to enlarge it.
Contact us to find out more!